

جدول محتوایی
GPT4ALL یک مدل ربات گفتگوی بزرگ منبع باز است که میتوانیم آن را روی لپتاپ یا دسکتاپ اجرا کنیم تا دسترسی آسانتر و سریعتری به ابزارهایی داشته باشیم که به روش جایگزین با مدلهای مبتنی بر ابر دریافت میکنید. این شبیه به مدل “ChatGPT” که بیشتر صحبت شده است کار می کند. اما مزیتی که ممکن است با استفاده از GPT4ALL داشته باشیم این است که زمان تأخیر جستجو و پاسخ را ندارد. همچنین، برای دسترسی به آن نیازی به ثبت نام در پلتفرم نداریم.
GPT4ALL بر اساس LLaMa و GPT-J است. این ابزارهای انعطاف پذیر و قدرتمند هوش مصنوعی را برای برنامه های مختلف ارائه می دهد. دادههای آموزشی برای GPT4ALL کوچکتر از دادههای آموزشی مدلهای GPT3 و GPT4ALL است که به این معنی است که این محدودیت باعث میشود این مدل در مقایسه با سایر مدلها از نظر قابلیت محدود باشد. علاوه بر این، این مدل بر روی ماشینهای محلی اجرا میشود، بنابراین ممکن است کندتر باشد و این به قابلیتهای پردازش و سرعت (CPU) سیستم بستگی دارد.

کار بر روی مدل GPT
GPT4 All دارای اتصالات پایتون برای هر دو رابط GPU و CPU است که به کاربران کمک می کند تا با استفاده از اسکریپت های Python با مدل GPT4 All تعامل ایجاد کرده و این مدل را در چندین برنامه ادغام کنند. این مدل همچنین به گسترش دامنه مدلهای زبان موجود و مدلهای پیشرفته سازگار کمک میکند. برای بزرگتر کردن این جامعه، از توسعه دهندگان قدردانی می شود که درخواست های جذب برای مشارکت غیرمستقیم در پروژه ارائه دهند.
این مقاله یک فرآیند گام به گام برای نصب GPT4All در اوبونتو و نصب سایر بسته های لازم برای تولید پاسخ با استفاده از مدل GPT4All ارائه می دهد. شروع به کار با مدل GPT4All ابتدا نیاز به نصب اجزای اجباری دارد. مطمئن شوید که پایتون از قبل روی سیستم شما نصب شده باشد. نسخه پیشنهادی پایتون نسخه 3.7 یا نسخههایی است که بعداً به آن میآیند. پس از آن، ما ملزم به انجام مراحل زیر هستیم:
مراحل نصب GPT
- ابتدا، با دانلود مخزن GPT4All از GitHub شروع کنید. پیوند این وب سایت در اینجا ذکر شده است https://github.com/nomic-ai/gpt4all.git. در ادامه این مرحله، نصب کننده GPT4All را برای سیستم عامل های مربوطه خود از وب سایت رسمی GPT4All دانلود می کنیم.
- فایل های دانلود شده را به هر دایرکتوری فایل در سیستم ما استخراج کنید.
- خط فرمان یا پنجره ترمینال را باز کنید و به دایرکتوری GPT4All بروید، جایی که فایل های دانلود شده را استخراج می کنیم.
- سپس دستور نصب بسته پایتون مورد نیاز را اجرا کنید.
مرحله 1: نصب
برای دانلود و نصب نیازمندی های بسته های پایتون و نصب GPT4All، دستور زیر را برای شروع نصب اجرا کنید:
python -m pip install -r requirements.txt
مرحله 2: مدل GPT4All را دانلود کنید
یا می توانیم مخزن GitHub را از لینک وب سایت GPT4All دانلود یا شبیه سازی کنیم. برای کلون کردن مخزن، دستور زیر را اجرا کنید:
کلون git https://github.com/nomic-ai/gpt4all.git
این دستور همانطور که در قطعه زیر نشان داده شده است، مخزن GPT4All را در ماشین های محلی ما کلون می کند:
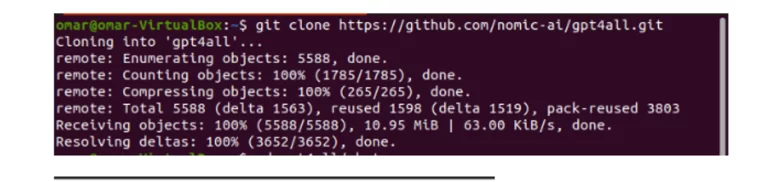
اگر از لینک ارائه شده برای دانلود نصب کننده GPT4All استفاده کرده ایم، باید مطمئن شویم که فایل مدل با پسوند .bin باشد. سپس، باید این فایل دانلود شده را در پوشه دایرکتوری چت که در آن GPT4All دانلود می شود، قرار دهیم.
مرحله 3: نقطه بازرسی مدل (اختیاری و فقط زمانی که مخزن را کلون کردیم قابل استفاده است)
اگر مخزن GPT4All را از پنجره فرمان (اوبونتو) کلون کردیم، باید فایل “.bin extension” را دانلود کنیم. برای این منظور افزونه را مستقیماً از این لینک “https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin” دانلود می کنیم.

پس از دانلود، این فایل را به پوشه چت که در مخزن کلون شده موجود است منتقل کنید.
مرحله 4: فایل را به پوشه چت منتقل کنید
اکنون باید به پوشه چت بروید. هنگامی که ما روی اوبونتو کار می کنیم، باید دستور زیر را اجرا کنیم که ما را به پوشه چت هدایت می کند. دستور به شرح زیر ذکر شده است:
یا مستقیماً نصب کننده GPT4 ll را از وب سایت GPT4All دانلود کردیم یا مخزن را کلون کردیم. در این مرحله، ما باید در همان مرحله ای باشیم که با موفقیت مخزن GPT4ALL را دانلود کرده و فایل دانلودی «.bin extension» آن را در فهرست چت در پوشه «GPT4All» قرار دادیم.
مرحله 5: مدل را اجرا کنید
وقتی به پوشه چت رفتیم، اکنون زمان اجرای مدل است. دستور زیر را در ترمینال لینوکس اجرا می کنیم:
لینوکس: ./gpt4all-lora-quantized-linux-x86
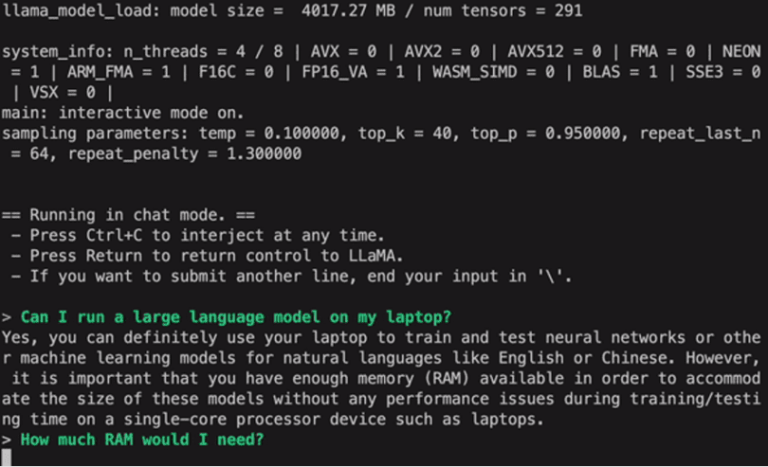
دستور شروع به اجرای مدل برای GPT4All می کند. اکنون میتوانیم از این مدل برای تولید متن از طریق تعامل با این مدل با استفاده از خط فرمان یا پنجره ترمینال استفاده کنیم یا ممکن است به سادگی هر سؤال متنی را که ممکن است داشته باشیم وارد کنیم و منتظر باشیم تا مدل به آن پاسخ دهد. این مدل بسته به مشخصات سیستم ما ممکن است کمی زمان پردازش داشته باشد. اما مزیتی که این مدل دسکتاپ نسبت به مدل های موجود در فضای ابری دارد این است که دیگر نگران مشکلات شبکه نخواهیم بود زیرا اکنون این مدل را روی سخت افزار محلی اجرا می کنیم.
ما با موفقیت GPT4all را روی دستگاه محلی خود اجرا کردیم. به خاطر داشته باشید که GPT4All هنوز در مراحل بهبود است، بنابراین ما باید اقساط خود را به روز نگه داریم. مخزن GPT4 All را می توان به راحتی در هر زمان به روز کرد. تنها کاری که باید انجام دهیم این است که به پوشه نصب اصلی مدل GPT4All برویم و به سادگی “Git pull” را درخواست کنیم. این مدل هنوز به دقت عملکرد ChatGPT دست پیدا نکرده است، اما هنوز با ارائه یک رابط دسکتاپ به کاربران خود از آن مدل ها متمایز است.
بخوانید: افزونه های ChatGPT در گوگل کروم
نتیجه
جایگزین مقیاس بزرگ، به راحتی در دسترس و منبع باز برای مدل هوش مصنوعی که مشابه GPT3 است، “GPT4 ALL” است. روش گام به گامی که در این راهنما توضیح دادیم را می توان برای استفاده از قدرت این مدل برای برنامه ها و پروژه های خود دنبال کرد. این مقاله به روش نصب مدل GPT4 All در اوبونتو می پردازد. ما به طور مفصل درباره روش کار این مدل با جوانب مثبت و منفی که به آن ضمیمه شده است بحث کردیم.
